Von LOD zu LOUD –
Erfahrungen aus zehn Jahren Linked-Open-Data-Publikation am hbz
Adrian Pohl /
@acka47 &
Pascal Christoph /
@dr0ide
Linked
Open Data, Hochschulbibliothekszentrum NRW (hbz)

Zürich, 2019-03-29
Diese Präsentation:
http://slides.lobid.org/htw-chur-2019/

Agenda Teil I
| 1. Kennenlernen | 13:15-13:30 |
| 2. Arbeitsweise | 13:30-14:00 |
| 3. Linked Open Data | 14:00-14:10 |
| 4. lobid | 14:10-14:30 |
| Pause | 14:30-15:00 |
Agenda Teil II
| 5. LOUD & JSON-LD | 15:00-15:30 |
| 6. Ein Beispiel: lobid-gnd | 15:30-16:00 |
| 7. lobid-Nutzungsbeispiele | 16:00-16:15 |
| 8. Abschlussdiskussion | 16:15-16:30 |
1. Kennenlernen
Linked Open Data im hbz
Im LOD-Programmbereich unterstützen wir die Etablierung und Pflege einer zukunftssicheren bibliothekarischen Dateninfrastruktur im regionalen, überregionalen und internationalen Raum.
Kernpunkte der hbz-LOD-Arbeit
Nutzung, Pflege und Unterstützung offener Infrastruktur
Forschung und Entwicklung
Wissens- und Technologietransfer
Wer macht was
Bibliothekar*innen (Adrian): Datenmodellierung & Standards, Metadaten-Formate, -Vokabulare, -Mappings, Functional Review
Entwickler*innen (Pascal, Fabian): Datentransformation, Administration, Indexierung, Web-APIs, Oberflächen
Rechner: 1 Web-Proxy, 3 Elasticsearch-Cluster-Knoten , 1 Indexierungrechner, 2 Web-Applikationsserver, 4 Spare- und Experimenterechner.
Pascal
2001-2006 Magister Sprachliche Informationsverarbeitung & Allgemeine Sprachwissenschaft & Phonetik, Uni zu Köln
2006-2008 Unix Sysad & Java Entwickler & Consultant, anykey GmbH
seit 2008 hbz, Köln
Produkte/Projekte: bis 2010 "Suchmaschine", dann "lobid"
Aufgaben: (Linux-)Administration und (Java-)Entwicklung. Open Source.
Adrian
1999-2007 Magister Kommunikationswissenschaften & Philosophie, RWTH Aachen
2009-2011 MALIS, FH Köln
seit 2008 hbz, Köln
Produkte/Projekte: vor allem lobid, aber auch Metadaten für Open Educational Resources (OER) & oerworldmap.org
Aufgaben: Datenmodellierung & Standards, Functional Review, Koordination & Kommunikation
Co-Chair der internationalen SWIB-Konferenz (Semantic Web in Bibliotheken)
Und ihr?
Schon von lobid gehört?
Wer hat schon ein Wikimedia-Projekt genutzt? Editiert?
Wer hat Wikidata geSPARQLt?
Wer hat schon von Creative Commons gehört? ...eine CC-Lizenz vergeben?
Wer hat schon eine JSON-Datei angeschaut? ...und verarbeitet?
2. Arbeitsweise
Openness
Gemeinsam ist allen LOD-Aktivitäten am hbz ein Bekenntnis zu einer offenen und transparenten Arbeitsweise
Sämtliche Entwicklungen auf Basis offener Webstandards
Softwarecode und Daten sind offen lizenziert (EPL & CC0)
Sämtliche Publikationen, Lehr- und Lernmaterialien im Web mit offener Lizenz veröffentlicht (siehe etwa slides.lobid.org)
Warum open?
Alternative zu einem in der Bibliothekswelt weit verbreiteten Vendor Lock-in
Voraussetzung für Tranzparenz und Nachnutzung
Verstärkt interinstitutionale Zusammenarbeit, verringert Doppelarbeiten
Erhöhte Sichtbarkeit der eigenen Arbeit
Motivationssteigernd
Pro & Contra "Open Source"
Schon Anfang der 2000er gab es Versuche offiziell Open Source im hbz zu produzieren
2010: Bedenken von Leitungsebenen ausräumen
(Nachspielen der Diskussion: Pro & Contra)
Open Source im hbz
2011 gingen Schreiben des hbz bis ins Innenministerium von NRW
Seitdem gibt es grünes Licht für Open-Source-Entwicklung
Mittlerweile >30 Open-Source-Produkte
Entwicklungsprozess
Open-Source-Entwicklung auf GitHub
GitHub
Eine Art Social Network für Softwareentwicklung
Wir entwickeln Open-Source-Software auf GitHub
Nicht nur Ergebnisse veröffentlichen, sondern den gesamten Prozess:
Planung, Issue-Tracking, Code, Testen, Diskussion, Teilen
GitHub Issues
GitHub hat einen integrierten Issue-Tracker
Primäres Organisationsmittel: beliebige Labels mit Farben
Integriert: Links zu Code, Commits, Usern, Markdown
Mehrere Repos
GitHub-Issues immer mit 1 GitHub-Repo assoziiert
Für einheitlichen Blick auf alle vom Team bearbeiteten Issues: Kanban-Board zur Visualisierung des Workflows
Waffle: Kanban-Board mit GitHub-Integration:
jedes Issue entspricht 1 Karte, Spalten entsprechen Labels
Prozess
Generell: Links → Rechts
| Backlog | Ready | Working | Review | Deploy | Done |
|---|---|---|---|---|---|
| Neue Issues ohne Label | Bereit, d.h. Anforderungen und Abhängigkeiten sind klar | In Bearbeitung | In Überprüfung | Bereit für Produktion | In Produktion |
Priorisierte Karten nach oben in der Spalte; Bugs generell priorisiert
Tägliche Treffen
Priorisierung unter anderem in täglichen kurzen Besprechungen
(vor dem Mittagessen, 12 Uhr, 5-15 Minuten)
Jeder: 1) Was zuletzt 2) Was aktuell, evtl. Probleme 3) Als nächstes
Wenn alle im hbz sind: im Stehen; sonst online (z.Zt.: Wire)
Planungstreffen
Nach Bedarf, alle paar Monate, längeres Planungstreffen (1-2 Std.)
Gemeinsam am Board Tickets durchgehen und priorisieren
3. Linked Open Data
Aufgabe
Verschicke einen Link zum Buch "With Reference to Reference" von Catherine Elgin
Gruppe 1: OPAC -> http://okeanos-www.hbz-nrw.de/F
Gruppe 2: lobid-resources -> https://lobid.org/resources
Warum LOD?
Überführung traditioneller bibl. Praktiken in das Web
Sichtbarkeit und Auffindbarkeit im Web erreichen
Nachnutzbarkeit ermöglichen
Synergieeffekte durch Verlinkung mit anderen Daten
Verbesserung der Recherchemöglichkeiten
Quelle: Pohl, Adrian / Ostrowski, Felix (2010): 'Linked Data' - und warum wir uns im hbz-Verbund damit beschäftigen." B.I.T. Online 13(3): S. 259-268. Preprint: http://hdl.handle.net/10760/14836Open Definition
Wissen ist offen, wenn jedeR darauf frei zugreifen, es nutzen, verändern und teilen kann – eingeschränkt höchstens durch Maßnahmen, die Ursprung und Offenheit des Wissens bewahren.http://opendefinition.org/od/2.1/de/
Linked Data: Best Practices
- Nutze URIs als Namen für Dinge
- Nutze HTTP-URIs, so dass Menschen sie aufrufen können
- Wenn jemand einen URI aufruft, biete nützliche Informationen an unter Nutzung der Standards (RDF*, SPARQL)
- Nimm Links zu anderen URIs auf, so dass weitere Dinge entdeckt werden können.
4. lobid
Linking open (bibliographic) data
Das Zentrum der im LOD-Programmbereich bereitgestellten Dienste
Dateninfrastruktur für Bibliotheken, Archive, Museen
Das hbz entwickelt seit 2009 Software im Bereich Linked Open Data (LOD)
Leitlinien
1. Publikation offen lizenzierter Daten (CC0) zur freien Nutzung
2. Nutzung domänenübergreifender Web-Standards
3. Bereitstellung von Web-APIs plus Rechercheoberflächen (Datenpflege erfolgt nach wie vor in Legacy-Systemen)
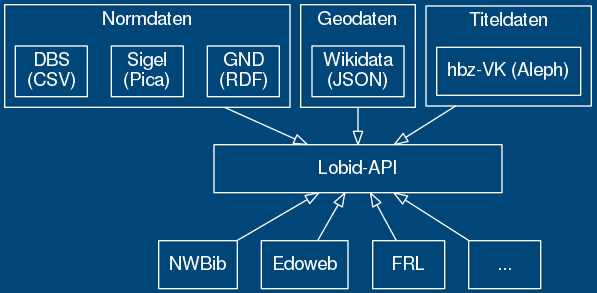
lobid-Dienste
lobid-resources: Daten des hbz-Verbundkatalogs
lobid-organisations: Daten des deutschsprachigen Sigelverzeichnisses und DBS-Stammdaten
lobid-gnd: Gemeinsame Normdatei
Datenquellen und -formate
Historie
Ein Reifeprozess in drei Phasen
2010-2013: Alpha-Betrieb
Forschung und Entwicklung
Datentransformation mit Perl-Skript, dann hbz-Tool
Publikation zunächst von RDF-Dateien, dann SPARQL
Jahrelanger Prozess zur offenen Lizenzierung der Verbunddaten
Der lange Weg zu Open Data
2010: Freigabe der Daten mit Beständen von vier Pionierbibliotheken (Pressemitteilung)
Wem gehören eigentlich die Daten eines Verbundkatalogs?
Es gab Bedenken aus einigen Verbundbibliotheken zur Freigabe des Gesamtkatalogs
Dazu kamen rechtliche Unklarheiten
Auftrag an Till Kreutzer einen rechtlichen Leitfaden zu verfassen, Kreutzer (2011)
Nach und nach stimmen immer mehr zu, am Ende Opt-out-Anfrage zur Freigabe des gesamten Katalogs
2013-2017: lobid v1.x
Erste Schritte Richtung Linked Open Usable Data: Von SPARQL zu LOD-API
Fokus auf Schnittstelle, keine Endnutzeroberflächen
Datentransformation mit Metafacture
seit 2017: lobid v2
Turning it LOUDer: What you see is what you can query (Details nach der Pause)
Oberfächenentwicklung
OpenRefine-Schnittstellen
Cool URIs for the Semantic Web:
Von 303 Redirect zu Hash URIs
Ontologien/Vokabulare
| lobid-resources | Applikationsprofil mit Properties/Klassen aus DC Terms, Bibframe, Bibliographic Ontology (Bibo) & anderen Klassen soviel viel eigenen Ergänzungen (lobid-vocab) (Blogpost) |
| lobid-organisations | Fast ausschließlich schema.org |
| lobid-gnd | Eigens an der DNB entwickelte Ontologie zur LOD-Publikation der GND (GND-Ontologie) |
Pause
5. LOUD & JSON-LD
Zur Entstehung von JSON-LD
RDF, SPARQL, Semantic Web – Not in my backyard!
Stop mentioning RDF and the Semantic Web.
Focus on tools for developers.
Do more dogfooding.
– Manu Sporny, damals Vorsitzender der RDFa Working Group beim W3C, der JSON-LD Community Group & Mitglied weiterer Semantic-Web-Gruppen, beim Schreiben an der JSON-LD-Spezifikationsiehe Sporny (2012)
Ultimately, RDF and the Semantic Web are of no interest to Web developers. They also have a really negative public perception problem. We should stop talking about them. Let’s shift the focus to be on Linked Data, explaining the problems that Web developers face today, and concrete, demonstrable solutions to those problems.ebd.
LOUD als neues Schlagwort?
Source: Rob Sanderson on twitter
LOUD: Grundannahme
Damit Daten nützlich sind, muss man die Zielgruppe kennen & eigene Angebote auf sie ausrichten
Hauptzielgruppe von LOD: Entwickler*innen oder Nutzer*innen von Software für Datenzugriff
und -manipulation
LOUD: Orientierung auf Bedürfnisse und Konventionen der Software-Entwicklung

Source: Rob Sanderson, "Shout it Out: LOUD", CC-BY (video)
Daten & Software
Daten werden mit Software bearbeitet (ausgewertet, ergänzt, integriert etc.)
Neue Applikationen entstehen, zur Interaktion mit einem Dataset
Existierende Applikationen zur Datenmaninpulation werden auf das Datenset angewendet
APIs
Software baut auf APIs auf
APIs machen Softwareentwicklung handhabbar (für 1st- und 2nd-Party-Software)
APIs ermöglichen Nutzung und Integration von 3rd-Party-Software
Zum Bsp. lobid-Formate und -Anwendungen
APIs entkoppeln Anwendungen von Datenquellen, Formaten und Systemen. Sie ermöglichen modulare, zukunftsfähige Applikationen.
Warum APIs?
★ Angemessenes Abstraktionslevel für die Zielgruppe
Daten werden mit Software verarbeitet
Software benötigt APIs
Kurz: brauchbare Daten sind Daten mit APIs
Aber wie APIs bereitstellen?
JSON (JavaScript Object Notation) über HTTP (Hypertext Transfer Protocol)
Der Web-API-Standard seit Jahren, siehe z.B. Target (2017)
JSON-Nutzungstrend
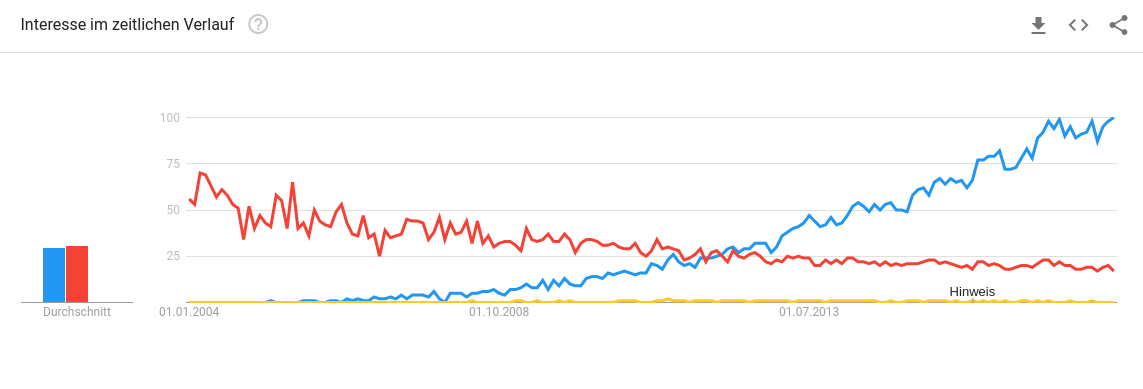
xml api json api sparql endpoint
10 % bis 19 % aller Domains haben eingebettetes JSON-LD
Quellen: Google Trends, Web Data Commons, W3TechsJSON
Ein einfaches, lesbares Key-Value-Format für strukturierte Daten
Key = String in Anführungszeichen
Values = object, array, number, string oder boolean
{ "foo": "bar" }
Beispiel:
GET https://api.github.com
{
"current_user_url": "https://api.github.com/user",
"authorizations_url": "https://api.github.com/authorizations",
"emails_url": "https://api.github.com/user/emails",
"emojis_url": "https://api.github.com/emojis",
"events_url": "https://api.github.com/events",
"feeds_url": "https://api.github.com/feeds",
"followers_url": "https://api.github.com/user/followers",
"gists_url": "https://api.github.com/gists{/gist_id}",
"hub_url": "https://api.github.com/hub",
...
}
JSON + Linked Data = JSON-LD
JSON-LD
"designed to be usable directly as JSON, with no knowledge of RDF" – Es ist richtiges JSON!
"also designed to be usable as RDF"
JSON-LD Keywords
@context mappt Strings für Properties & Klassen auf URIs
@id identifiziert die URI eines Nodes (das Subjekt)
@type ist multifunktional: legt 1.) die Klasse eines nodes (rdf:type) fest oder 2.) den Datentyp eines Literals
Sonstige: @value, @language, @container, @list, @set, @reverse, @index, @base, @vocab, @graph
Die wichtigsten LOUD-Prinzipien
★ Niedrige Einstiegshürden
★ Aus sich heraus verständlich
★ Konsistenz, kaum Ausnahmen
JSON != JSON
Wie erreiche ich Einfachheit, leichte Verständlichkeit und konsistente Daten?
Worauf muss ich achten?
Probieren wir das doch einmal aus
Übung: JSON-LD
Input: RDF
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<https://slides.lobid.org/htw-chur-2019/>
rdf:type foaf:Document ;
dcterms:title "Von LOD zu LOUD – Erfahrungen aus zehn Jahren Linked-Open-Data-Entwicklung am hbz";
dcterms:creator <http://lobid.org/team/ap#!>, <http://lobid.org/team/pc#!> ;
dcterms:subject <http://d-nb.info/gnd/7863462-3> , <http://d-nb.info/gnd/1064023886> ;
dcterms:license <https://creativecommons.org/licenses/by/4.0/> .
<http://lobid.org/team/ap#!> rdf:type foaf:Person ;
foaf:name "Adrian Pohl" .
<http://lobid.org/team/pc#!> rdf:type foaf:Person ;
foaf:name "Pascal Christoph" .Schritt 1
Überführe die Turtle-Datei in JSON-LD.
Nutze dafür den RDF Translator.
Ergebnis 1
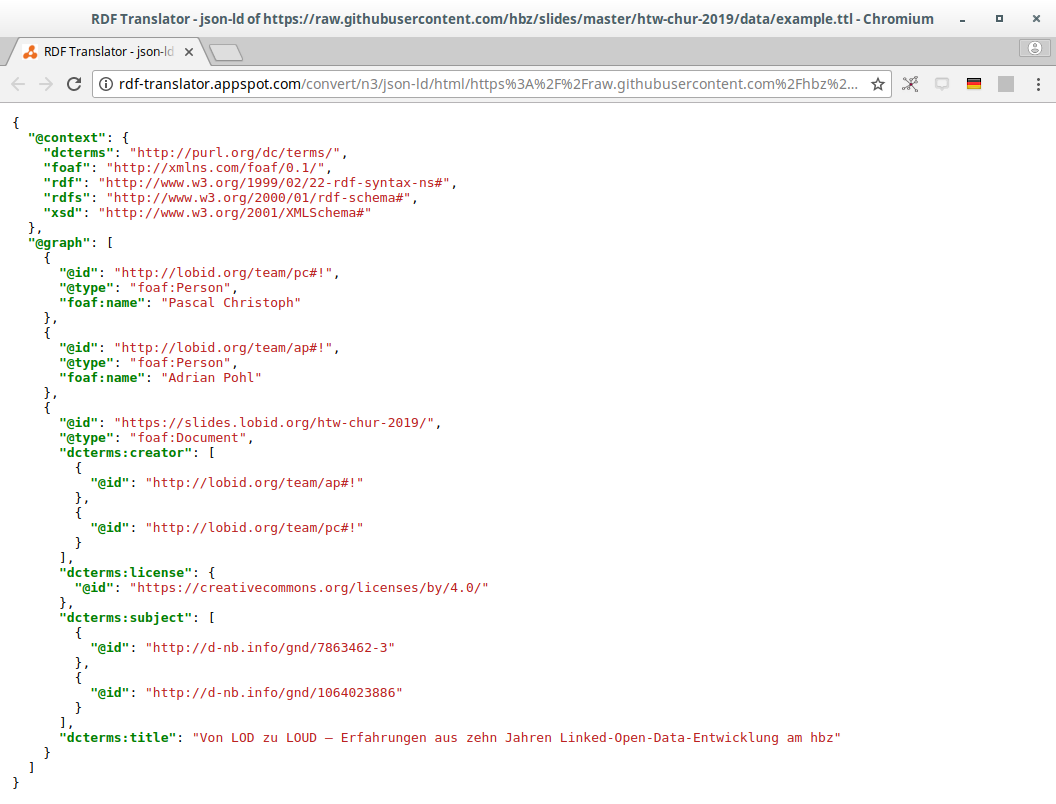
Problem
@graph-Array und flache Struktur
Lösungsansatz: JSON-LD-Framing
Schritt 2
Füge das JSON-LD in den JSON-LD Playground ein und überführe es in eine Baumstruktur, indem du diesen Frame anwendest:
{
"@context": {
"dcterms": "http://purl.org/dc/terms/",
"foaf": "http://xmlns.com/foaf/0.1/"
},
"@type": "foaf:Document",
"@embed": "@always"
}Entferne anschließend das @graph-Array.
Ergebnis 2
{
"@context": {
"dcterms": "http://purl.org/dc/terms/",
"foaf": "http://xmlns.com/foaf/0.1/"
},
{
"@id": "https://slides.lobid.org/htw-chur-2019/",
"@type": "foaf:Document",
"dcterms:creator": [
{
"@id": "http://lobid.org/team/pc#!",
"@type": "foaf:Person",
"foaf:name": "Pascal Christoph"
},
{
"@id": "http://lobid.org/team/ap#!",
"@type": "foaf:Person",
"foaf:name": "Adrian Pohl"
}
],
"dcterms:license": {
"@id": "https://creativecommons.org/licenses/by/4.0/"
},
"dcterms:subject": [
{
"@id": "http://d-nb.info/gnd/7863462-3"
},
{
"@id": "http://d-nb.info/gnd/1064023886"
}
],
"dcterms:title": "Von LOD zu LOUD – Erfahrungen aus zehn Jahren Linked-Open-Data-Entwicklung am hbz"
}
}Schritt 3
Namespace-Präfixe sind unschön
Passe den Kontext an, so dass die Schlüssel & Typen keine Präfixe mehr enthalten ("dcterms:creator" -> "creator" etc.)
{
"@context": {
"creator": "http://purl.org/dc/terms/creator",
"name": "http://xmlns.com/foaf/0.1/name",
"license": "http://purl.org/dc/terms/license",
"subject": "http://purl.org/dc/terms/subject",
"title": "http://purl.org/dc/terms/title",
"Document": "http://xmlns.com/foaf/0.1/Document",
"Person": "http://xmlns.com/foaf/0.1/Person"
}
}Ergebnis 3
{
"@context": {
"creator": "http://purl.org/dc/terms/creator",
"name": "http://xmlns.com/foaf/0.1/name",
"license": "http://purl.org/dc/terms/license",
"subject": "http://purl.org/dc/terms/subject",
"title": "http://purl.org/dc/terms/title",
"Document": "http://xmlns.com/foaf/0.1/Document",
"Person": "http://xmlns.com/foaf/0.1/Person"
},
"@id": "https://slides.lobid.org/htw-chur-2019/",
"@type": "Document",
"creator": [
{
"@id": "http://lobid.org/team/pc#!",
"@type": "Person",
"name": "Pascal Christoph"
},
{
"@id": "http://lobid.org/team/ap#!",
"@type": "Person",
"name": "Adrian Pohl"
}
],
"license": {
"@id": "https://creativecommons.org/licenses/by/4.0/"
},
"subject": [
{
"@id": "http://d-nb.info/gnd/7863462-3"
},
{
"@id": "http://d-nb.info/gnd/1064023886"
}
],
"title": "Von LOD zu LOUD – Erfahrungen aus zehn Jahren Linked-Open-Data-Entwicklung am hbz"
}Schritt 4
@'s sind verwirrend, URIs nicht aus sich heraus verständlich
(Im Idealfal hat jede URI ein Label und einen Typ.)
a) Nutze "id" und "type" als Aliase für die JSON-LD-Keywords "@id" und "@type". (Playground)
b) Ergänze Name und Typ für verlinkte Ressourcen.
Ergebnis 4
{
"@context": {
"id": "@id",
"type": "@type",
"creator": "http://purl.org/dc/terms/creator",
"name": "http://xmlns.com/foaf/0.1/name",
"license": "http://purl.org/dc/terms/license",
"subject": "http://purl.org/dc/terms/subject",
"title": "http://purl.org/dc/terms/title",
"Document": "http://xmlns.com/foaf/0.1/Document",
"Person": "http://xmlns.com/foaf/0.1/Person",
"License": "http://purl.org/dc/terms/LicenseDocument",
"SubjectHeading": "http://d-nb.info/standards/elementset/gnd#SubjectHeadingSensoStricto"
},
"id": "https://slides.lobid.org/htw-chur-2019/",
"type": "Document",
"creator": [
{
"id": "http://lobid.org/team/pc#!",
"type": "Person",
"name": "Pascal Christoph"
},
{
"id": "http://lobid.org/team/ap#!",
"type": "Person",
"name": "Adrian Pohl"
}
],
"license": {
"id": "https://creativecommons.org/licenses/by/4.0/",
"type": "License",
"name": "Creative Commons Attribution 4.0 International (CC BY 4.0)"
},
"subject": [
{
"id": "http://d-nb.info/gnd/7863462-3",
"type": "SubjectHeading",
"name": "Linked Data"
},
{
"id": "http://d-nb.info/gnd/1064023886",
"type": "SubjectHeading",
"name": "Open Data"
}
],
"title": "Von LOD zu LOUD – Erfahrungen aus zehn Jahren Linked-Open-Data-Entwicklung am hbz"
}Schritt 5
Problem: Der Kontext nimmt viel Raum ein, so dass die eigentlichen Daten in den Hintergrund rücken.
Lösung: Lagere den Kontext in eine externe Datei aus & verlinke ihn aus den Daten.
Ergebnis 5 (Endergebnis)
{
"@context": "http://lobid.org/labs/htw-chur-2019-context.jsonld",
"id": "https://slides.lobid.org/htw-chur-2019/",
"type": "Document",
"creator": [
{
"id": "http://lobid.org/team/pc#!",
"type": "Person",
"name": "Pascal Christoph"
},
{
"id": "http://lobid.org/team/ap#!",
"type": "Person",
"name": "Adrian Pohl"
}
],
"license": {
"id": "https://creativecommons.org/licenses/by/4.0/",
"type": "License",
"name": "Creative Commons Attribution 4.0 International (CC BY 4.0)"
},
"subject": [
{
"id": "http://d-nb.info/gnd/7863462-3",
"type": "SubjectHeading",
"name": "Linked Data"
},
{
"id": "http://d-nb.info/gnd/1064023886",
"type": "SubjectHeading",
"name": "Open Data"
}
],
"title": "Von LOD zu LOUD – Erfahrungen aus zehn Jahren Linked-Open-Data-Entwicklung am hbz"
}6. Ein Beispiel: lobid-gnd
a. Die Oberfläche
Demo
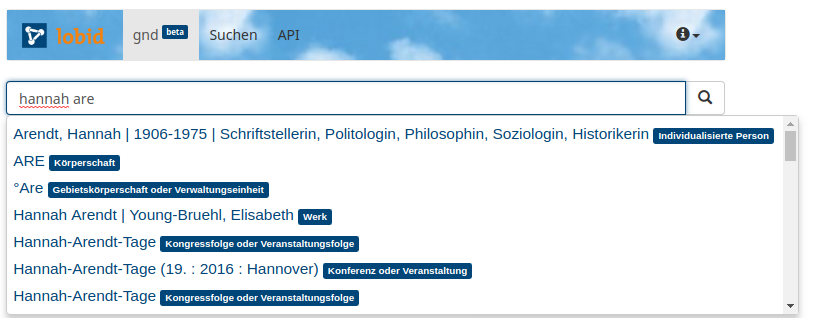
https://lobid.org/gndAuto Suggest
Ergebnisliste
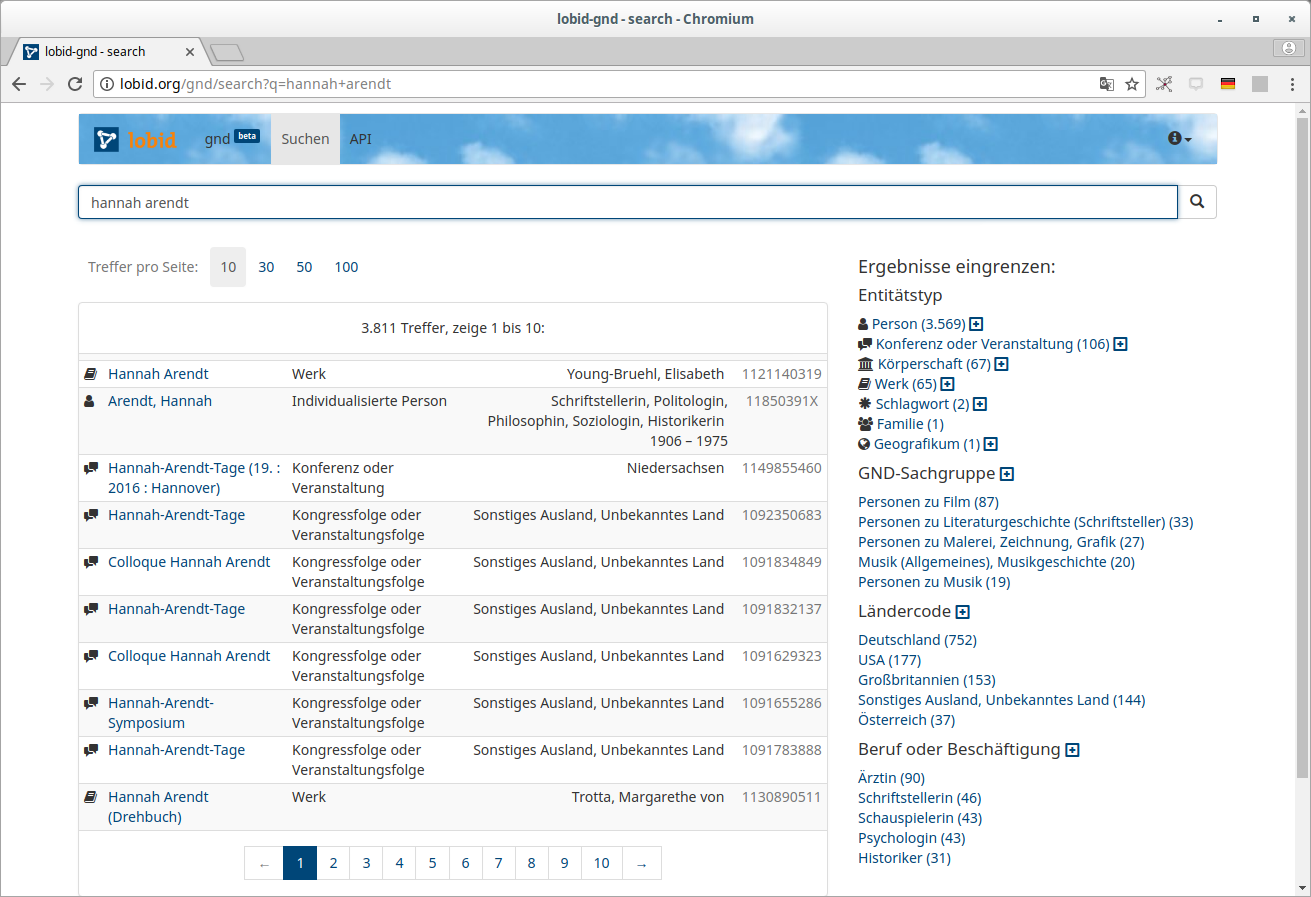
Einzeltreffer
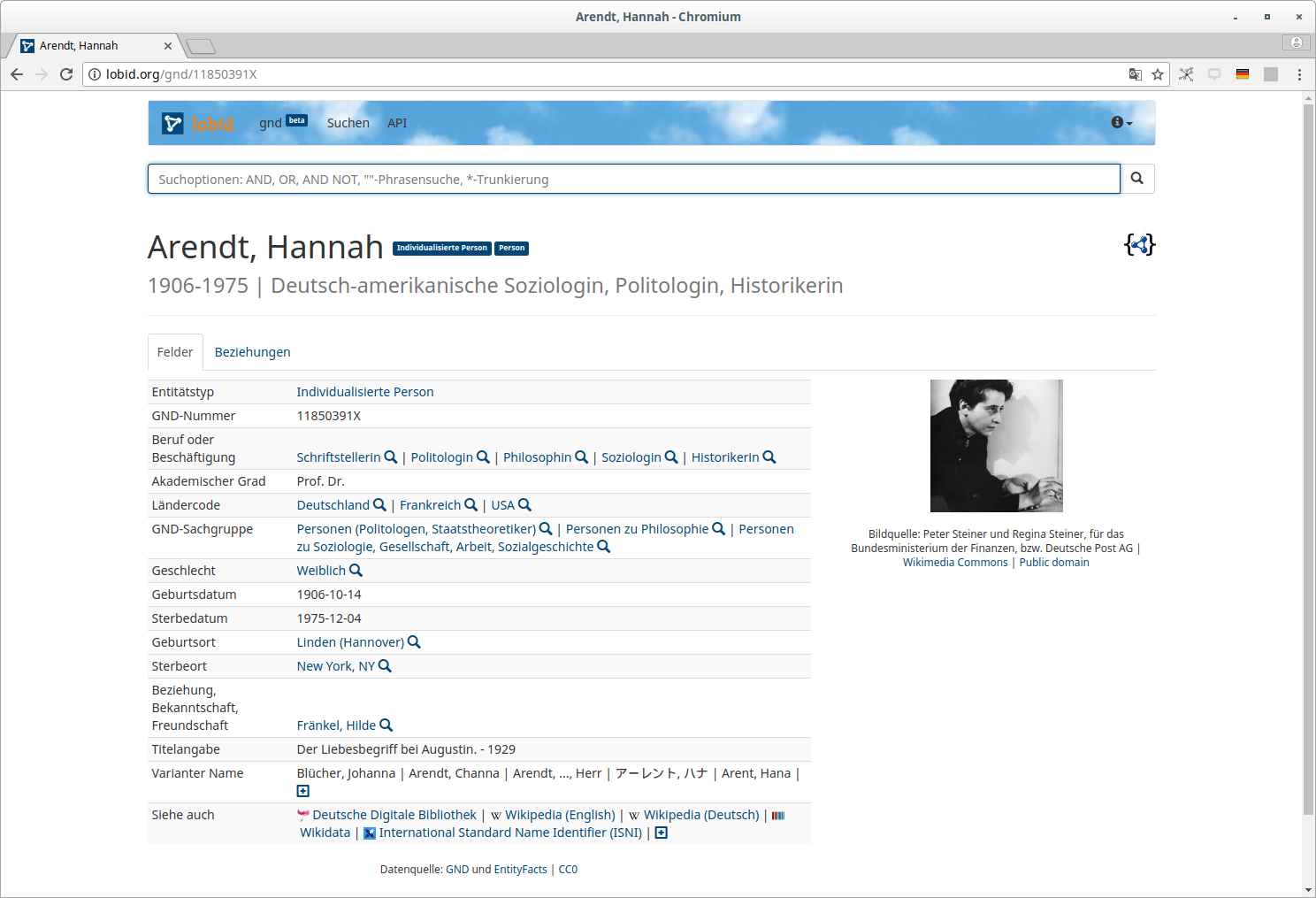
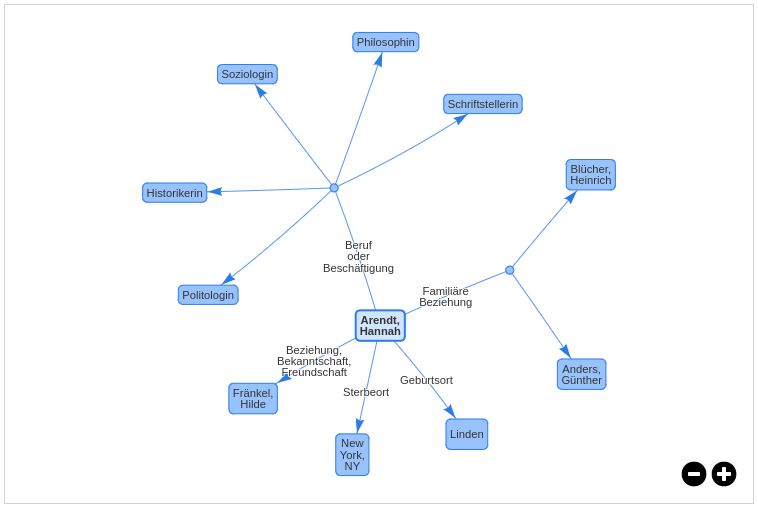
Beziehungsgraph
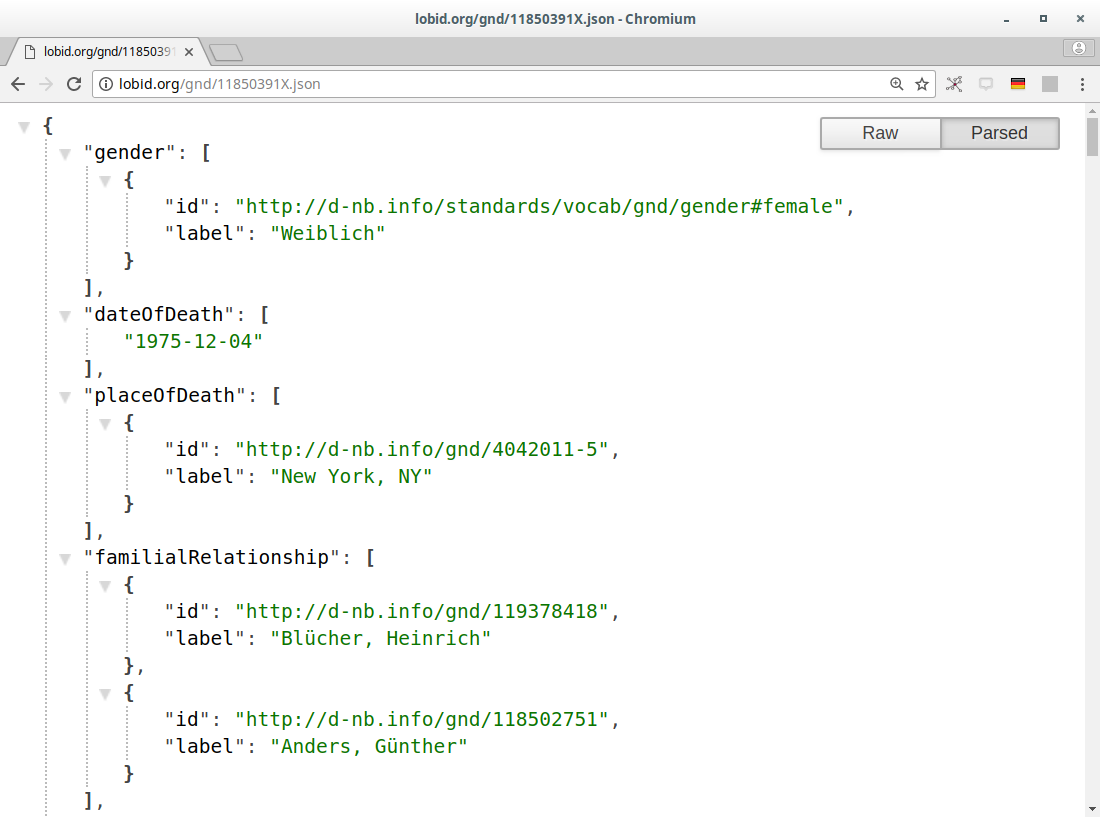
b. Die Daten
JSON(-LD)
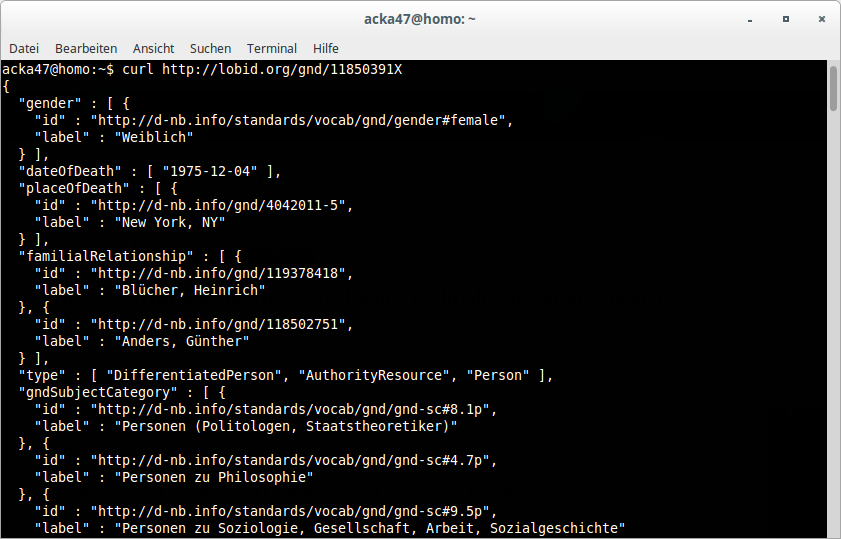
Datenherkunft & -generierung
Tägl. Bezug der GND-RDF-Daten von der DNB via OAI-PMH
Konversion nach JSON-LD mittels @context, Framing etc.
Homogenisierung von Typen und Label-Properties
Labels für verlinkte Ressourcen ergänzen
Anreicherung mit EntityFacts-Links und -Bildern
Et voilà: Linked Open Usable Data (LOUD)
c. Web-API
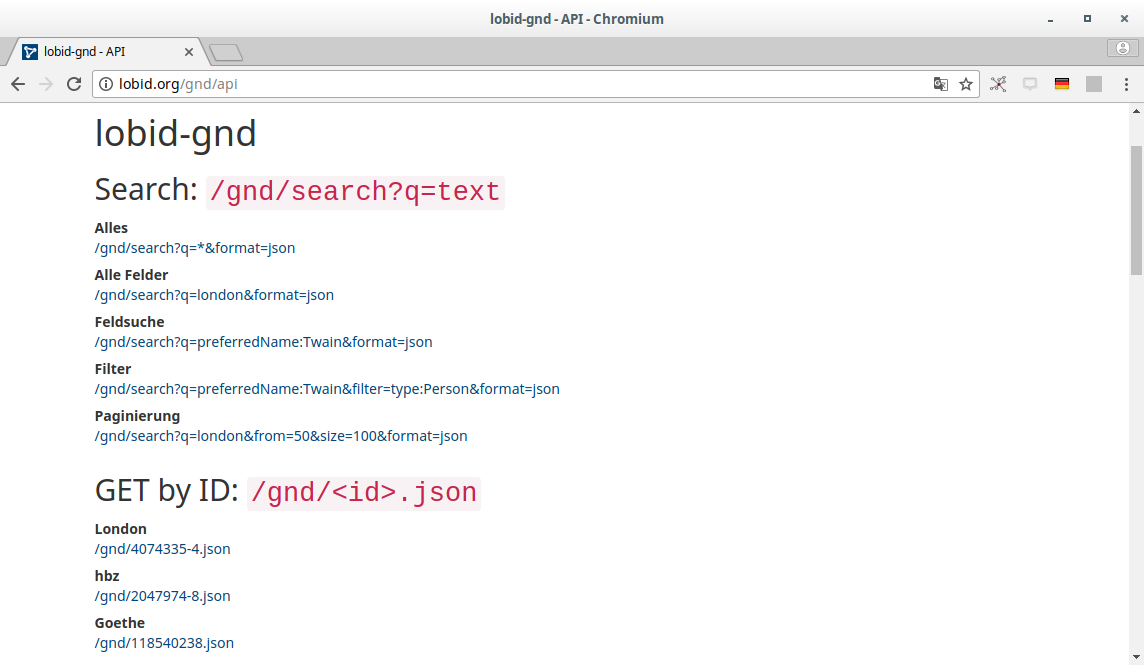
Abfrage-Möglichkeiten
JSON-LD-Daten in Elasticsearch-Index
Elasticsearch bzw. Lucene Suchsyntax
OpenRefine Reconciliation Endpoint
Für Einzeltreffer andere RDF-Serialisierungen per Content Negotiation
Beispiel-Abfragen
Personen, die während der NS-Zeit in Köln geboren wurden
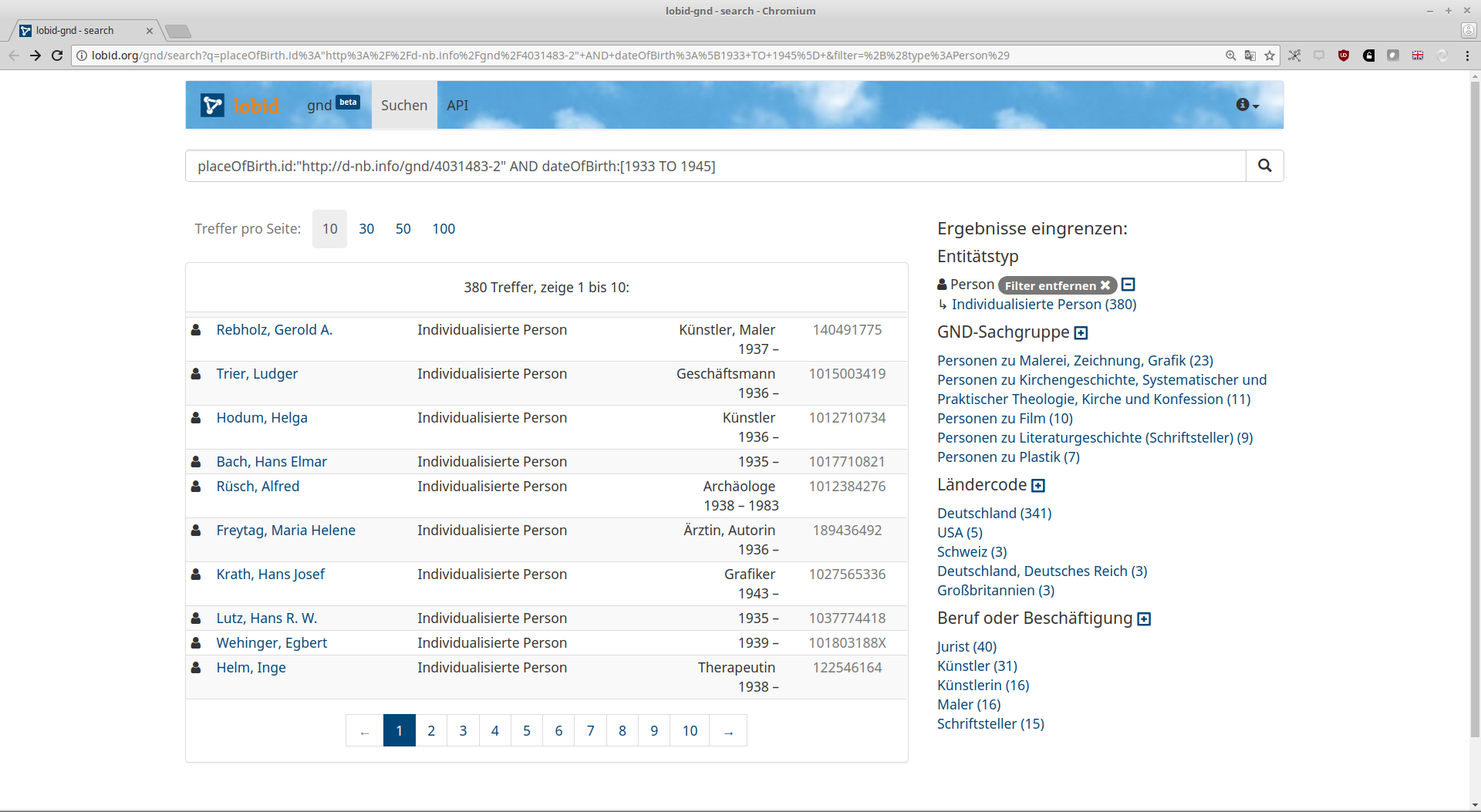
Alle Entitäten, zu denen ein Architekt angegeben wurde
Kibana-Visualisierungen
http://kibana.lobid.org/app/kibana#/visualizeAufgabe
Suche nach allen Personen in der GND, die in Chur geboren wurden und in Zürich gestorben sind.
7. lobid-Nutzungsbeispiele
Verbundbibliotheken auf hbz-Website
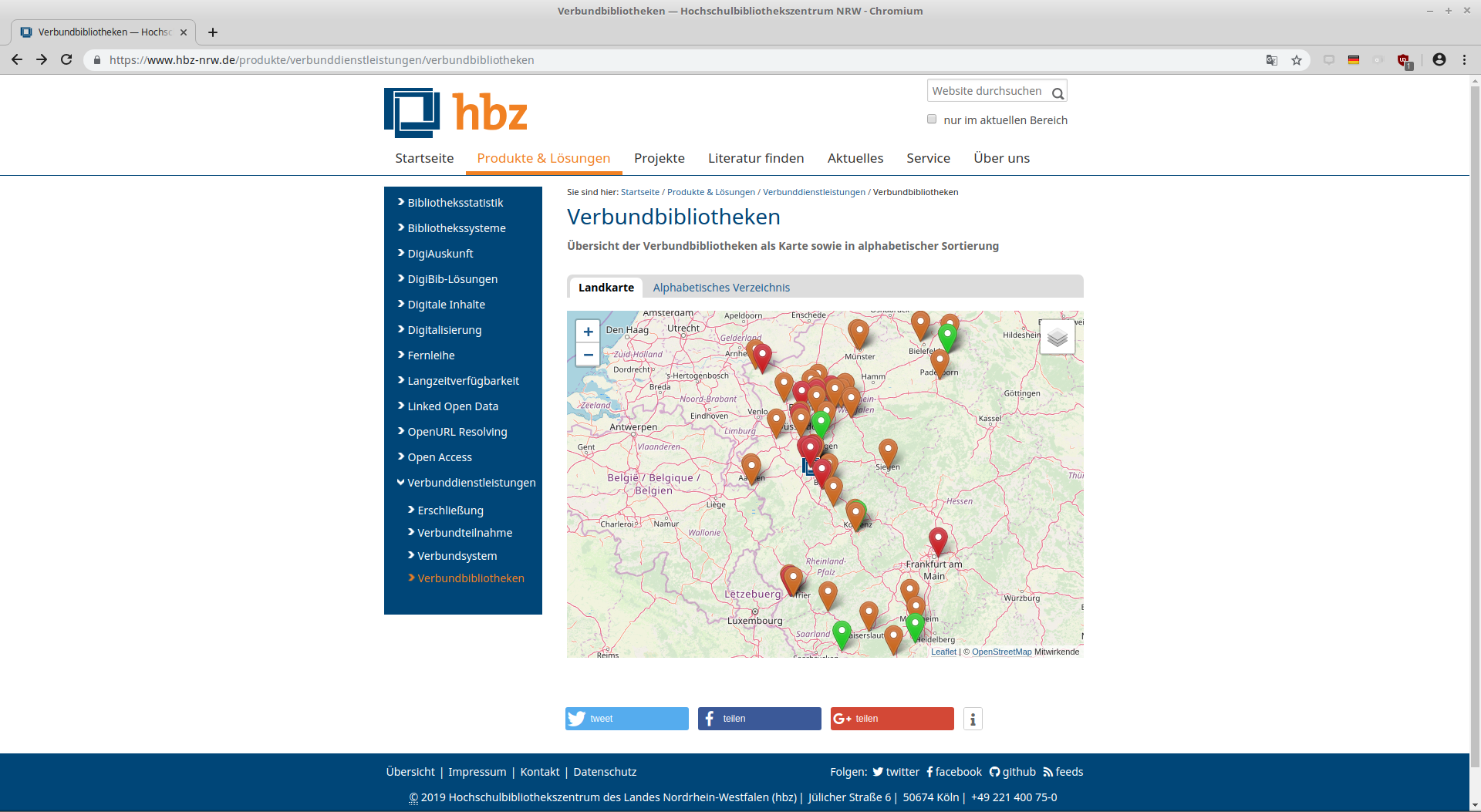
Basiert auf lobid-organisations
Repositorien
https://www.edoweb-rlp.de/ & https://repository.publisso.de/ nutzen lobid-resources Daten
Im Erfassungsformular: Nutzung des GND-ID-Lookups von lobid-gnd
Nordrhein-Westfälische Bibliographie (NWBib)
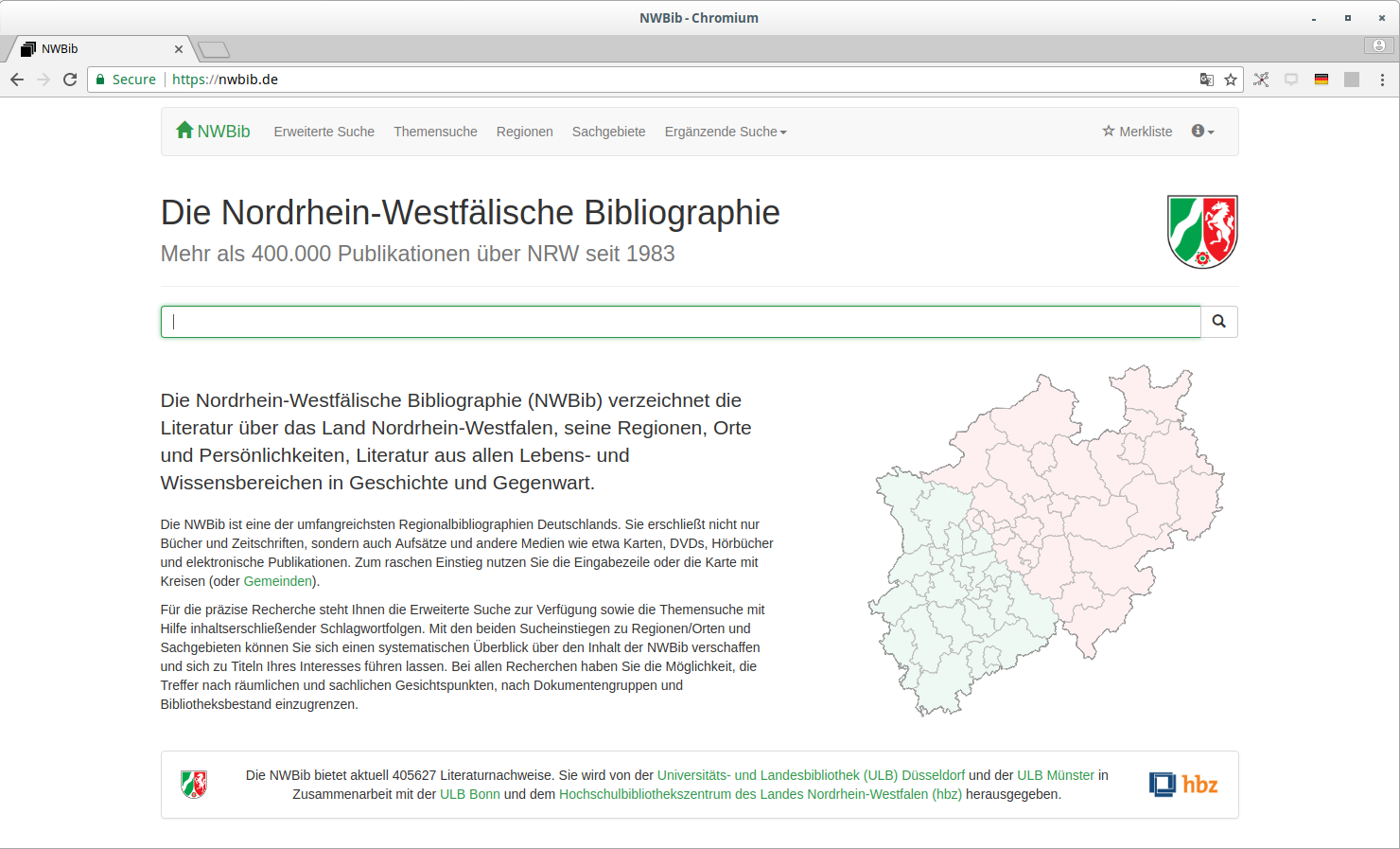
NWBib
Basiert vollständig auf der lobid-API
Nutzt das NWBib-Subset von lobid-resources
Informationen zu besitzenden Bibliotheken von lobid-organisations
Themenvorschläge auf Basis von lobid-gnd
NWBib-Suchergebnisliste
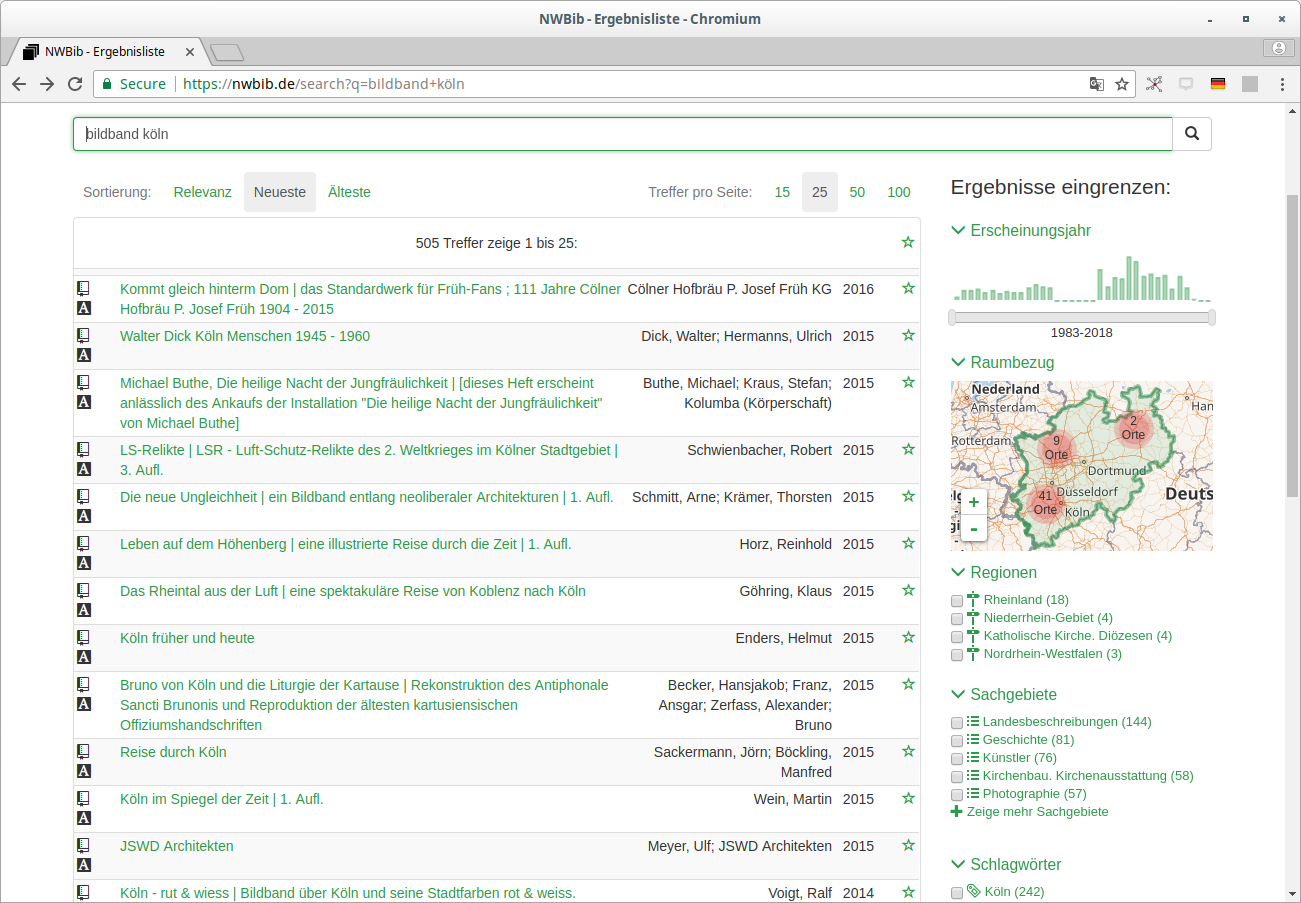
Anfrage gegen das NWBib-Subset in lobid-resources
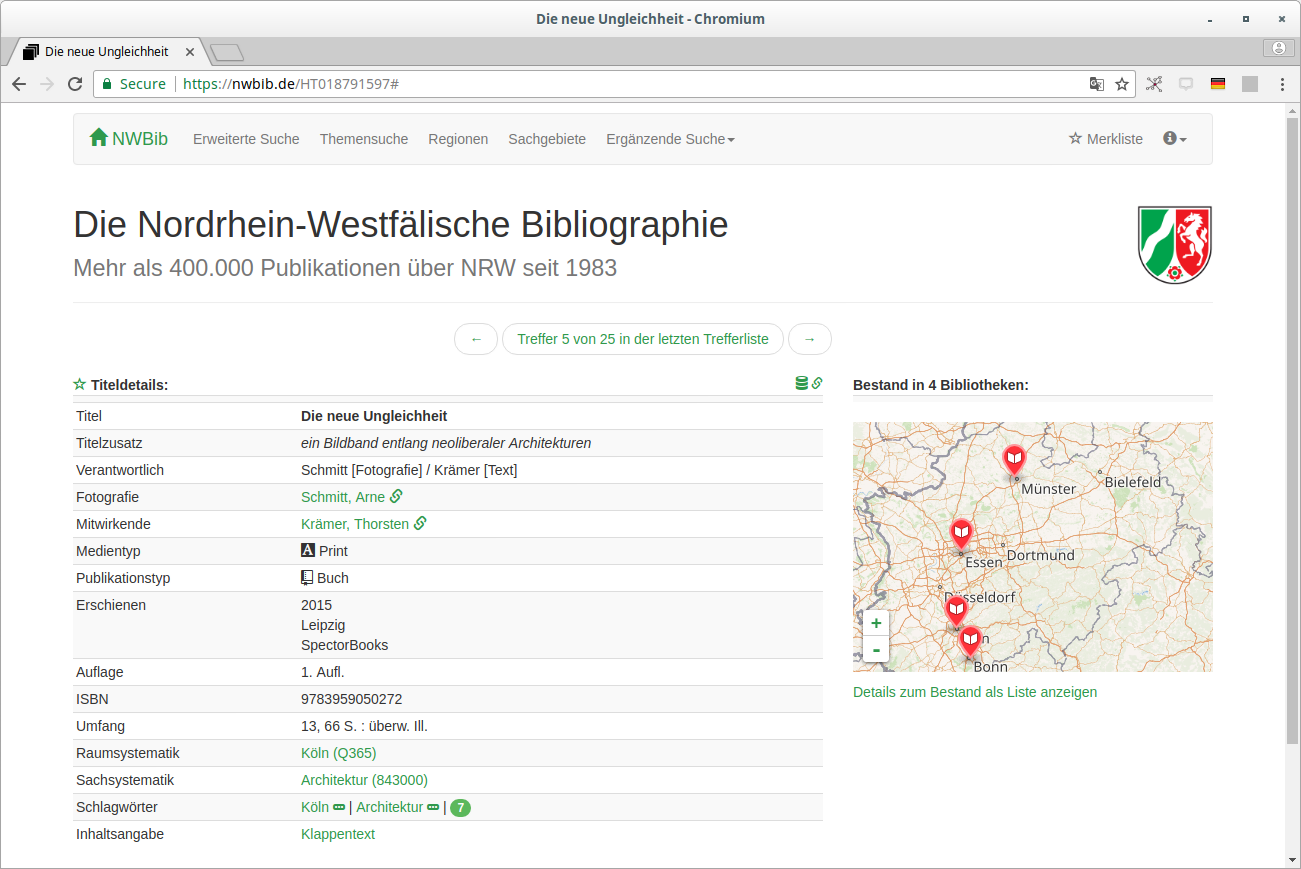
Informationen zu besitzenden Bibliotheken (Name, URL, Standort) werden aus lobid-organisations geladen
Virtuelle Deutsche Landesbibliographie
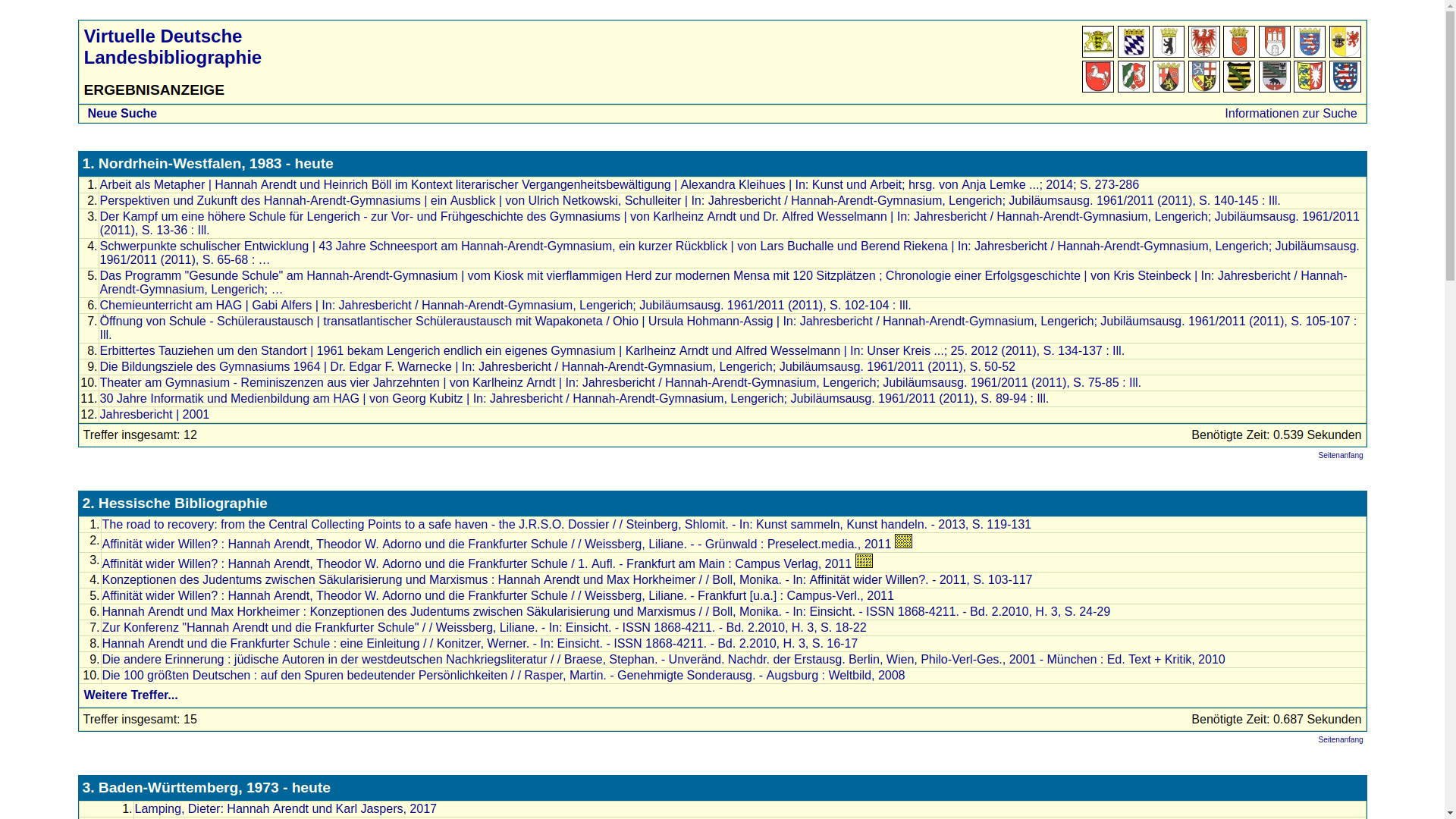
Seit April 2018 ist nwbib.de über die lobid-API in die VDL integriert.
Bibliothekskatalog des Juristischen Seminars der ULB Bonn
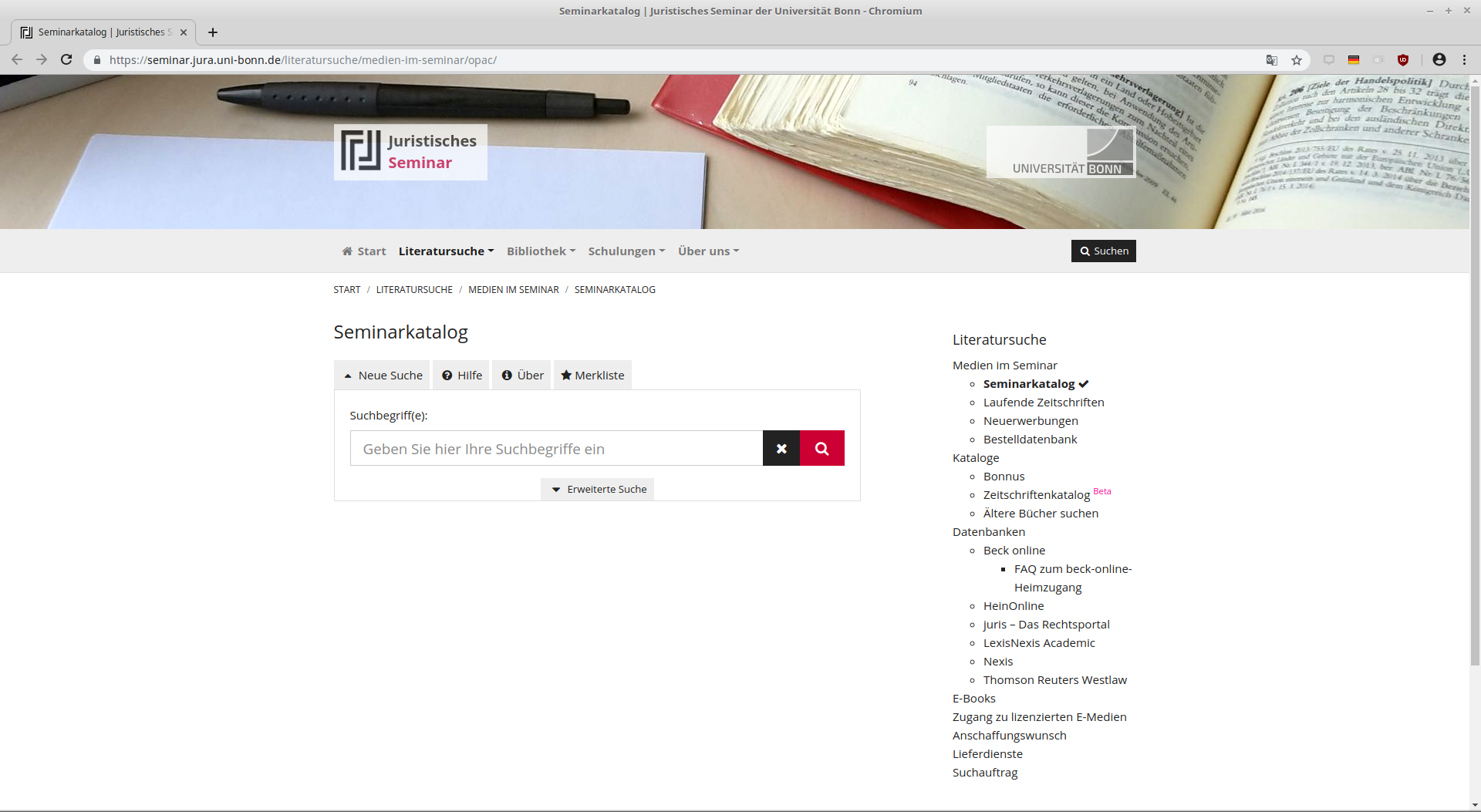
Bulk Download der Daten mit Bestand in DE-5-34
"Katalog plus" der UB Dortmund
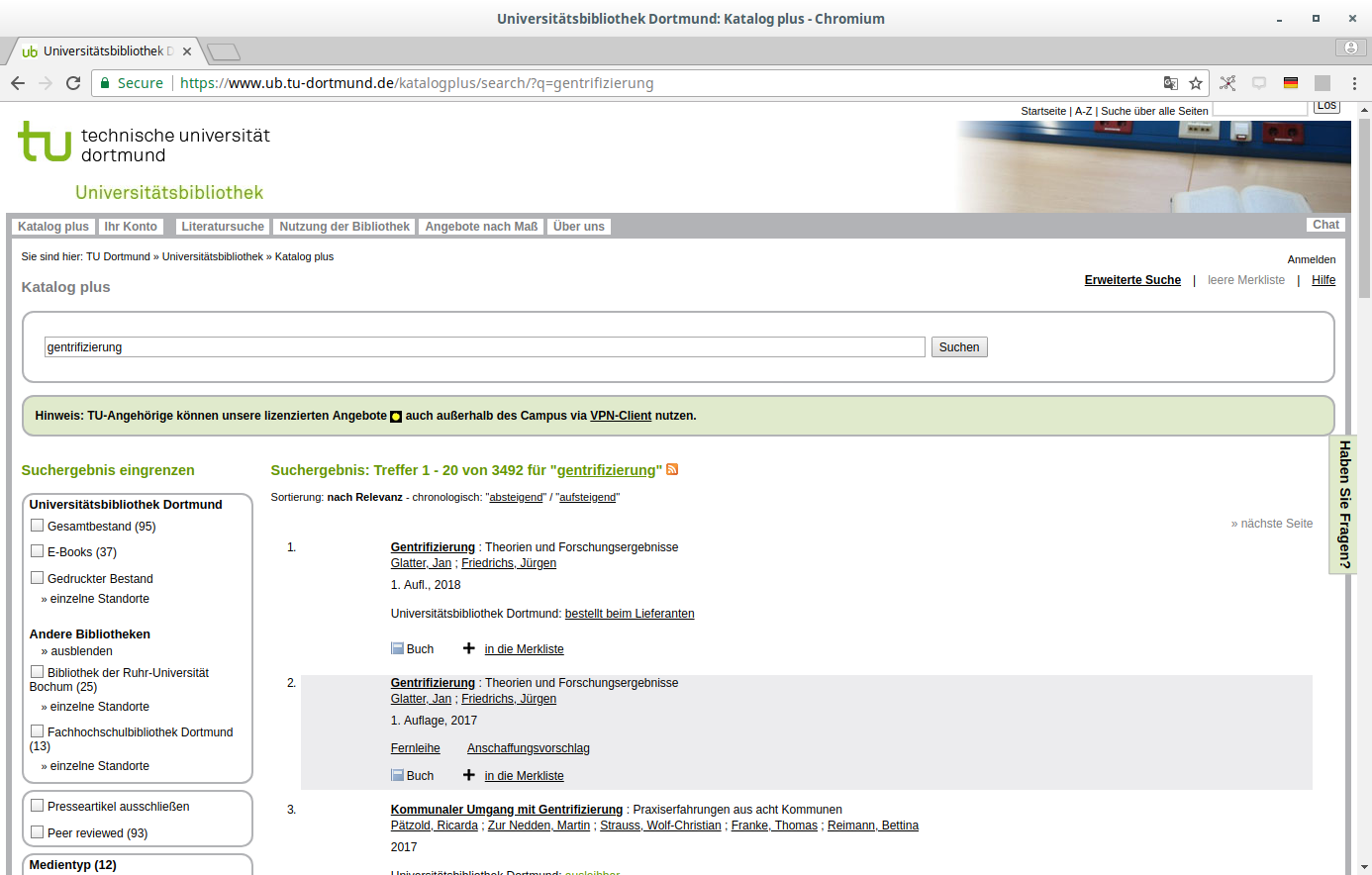
Daten zu den Beständen der UB & einiger umliegender Bibliotheken werden täglich von lobid geholt, transformiert und in den Index geladen
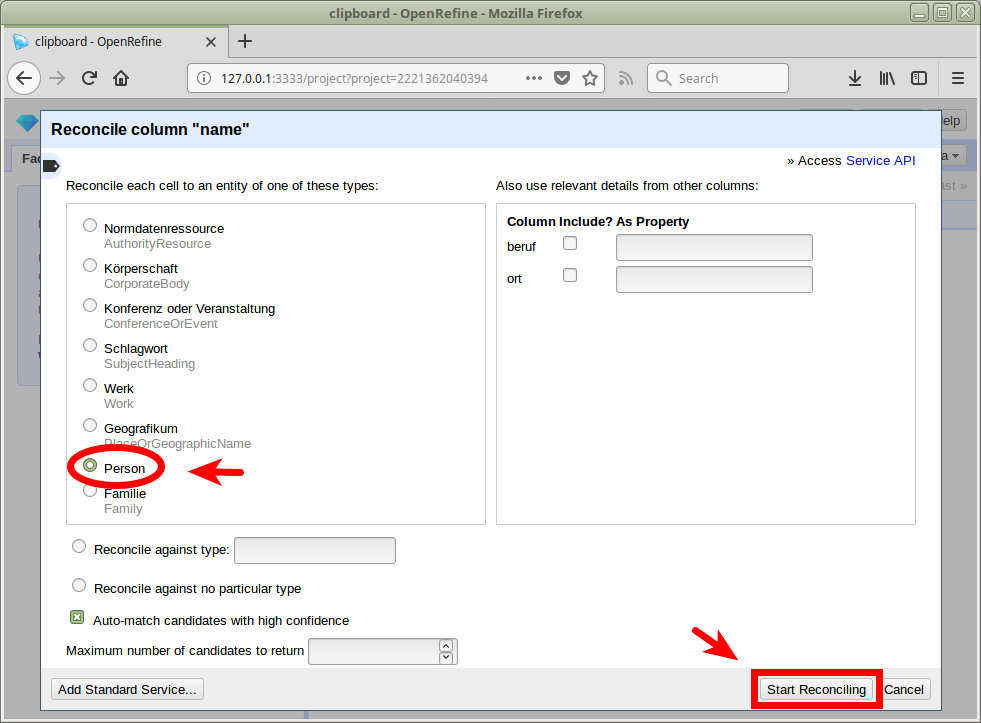
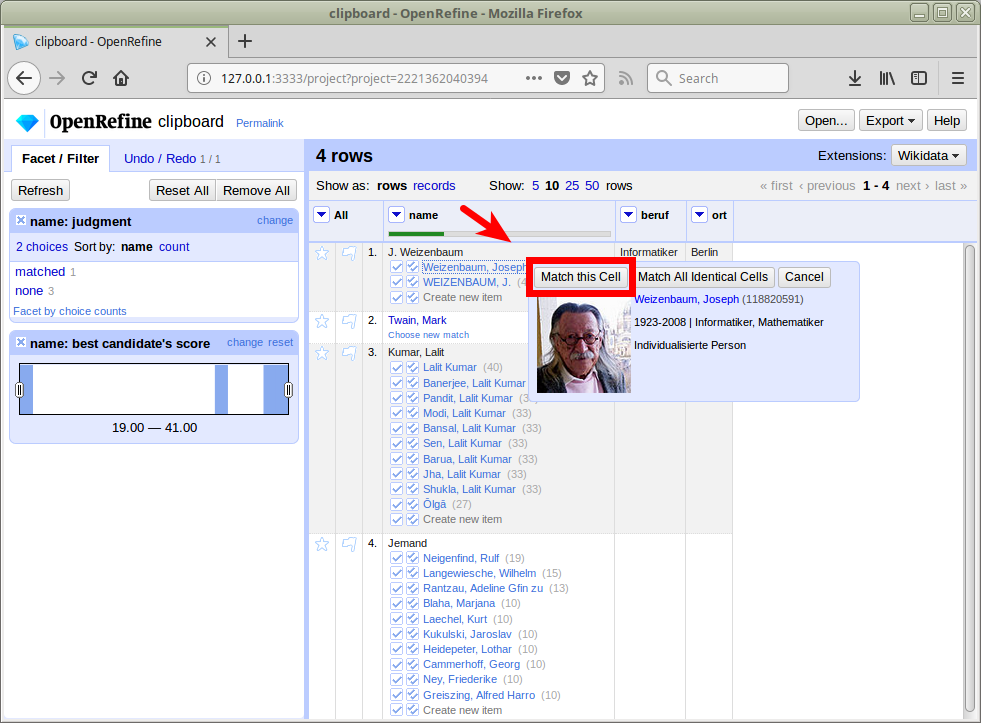
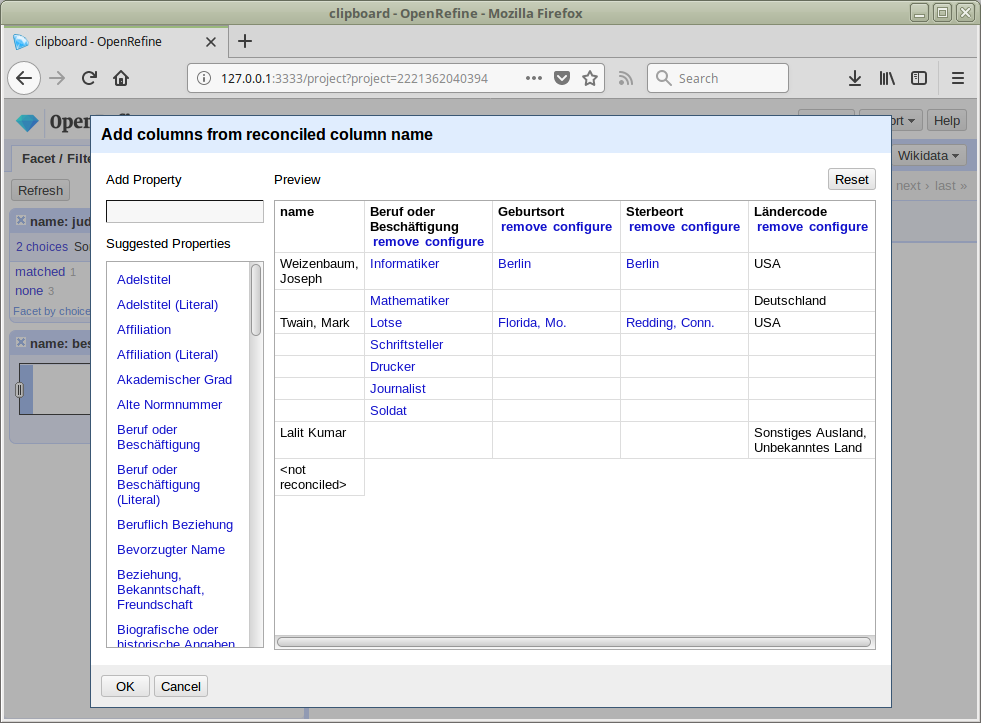
Reconciliation mit OpenRefine
Matchen auf GND-Ressourcen in OpenRefine
Übernahme von Daten aus spezifischen Feldern mittels Data Extension API
lobid-gnd ist der zweite Dienst nach Wikidata, der die Data Extension API unterstützt
Große Resonanz auf das Angebot, insbesondere aus den Digital Humanities
Aufgabe (falls noch Zeit ist...)
Lade diese Liste nach OpenRefine, matche die Einträge mit der GND und ergänze Berufe und Wirkungsorte.
id,name
1,Haddaway
2,Johannes Geßner
3,Judith Kuckart
4,Rosa Luxemburg
5,Albert Einstein
6,Hazel Brugger
7,Anne Cuneo
8,Vitus Huonder8. Abschlussdiskussion

Weiterführende Informationen
- lobid-Blog
- lobid auf Twitter und Mastodon
- Kreutzer, Till (2011): Open Data – Freigabe von Daten aus Bibliothekskatalogen. Hg. v. Hochschulbibliothekszentrum des Landes Nordrhein-Westfalen (PDF)
- Pohl, Adrian / Steeg, Fabian / Christoph, Pascal (2018): lobid – Dateninfrastruktur für Bibliotheken. In: Informationspraxis 4(1). https://doi.org/10.11588/ip.2018.1.52445
- Sporny, Manu (2012): The Problem with RDF and Nuclear Power. URL: http://manu.sporny.org/2012/nuclear-rdf/
- Steeg, Fabian / Pohl, Adrian / Christoph, Pascal (2019): lobid-gnd – Eine Schnittstelle zur Gemeinsamen Normdatei für Mensch und Maschine. In: Informationspraxis 5(1). https://doi.org/10.11588/ip.2019.1.52673
- Target, Sinclair (2017): The Rise and Rise of JSON. URL: https://twobithistory.org/2017/09/21/the-rise-and-rise-of-json.html